[이기적] 이상값(Outlier) 처리 방법 정리 (Box Plot · Z-score · DBSCAN · Isolation Forest)
2026. 3. 9. 03:28ㆍCertifications/빅데이터분석기사 필기
💡 이상값(Outlier) 은 데이터 분석 결과를 왜곡할 수 있는 중요한 요소이다.
이상값은 데이터 수집 과정의 오류 또는 자연적 발생에 의해 나타날 수 있으며,
데이터 전처리 과정에서 적절한 탐지와 처리 과정이 필요하다.
1️⃣ 이상값(Outlier)의 개념
✅ 이상값 정의
- 데이터 집합에서 정상 범위를 벗어난 값
- 일반적인 패턴과 현저히 다른 관측값
🔹 발생 원인
- 데이터 입력 오류
- 측정 오류
- 실험 환경 오류
- 자연적 극단값 발생
🎯 포인트
- 이상값 = Outlier
- 데이터 분포에서 정상 범위를 벗어난 값
2️⃣ 이상값의 종류
| 구분 | 설명 | 예시 |
|---|---|---|
|
단변수 이상치 (Univariate Outlier) |
하나의 변수 분포에서 발생하는 이상값 |
키 데이터에서 300cm 시험 점수에서 0점 또는 1000점 |
|
다변수 이상치 (Multivariate Outlier) |
여러 변수 간 관계에서 벗어나는 데이터 | 키 180cm / 몸무게 20kg |
🎯 포인트
- 단변수 이상치 → Univariate
- 다변수 이상치 → Multivariate
3️⃣ 이상값 발생 원인
| 구분 | 설명 | 예시 |
|---|---|---|
|
비자연적 이상치 (Artificial Outlier) |
데이터 수집 및 처리 과정에서 발생하는 오류로 인해 나타나는 이상값 |
입력 오류 측정 오류 실험 오류 데이터 처리 오류 표본 추출 오류 |
|
자연적 이상치 (Natural Outlier) |
실제 환경에서 자연적으로 발생하는 극단적인 값 |
초고소득자 극단적인 자연현상 |
🎯 포인트
- 오류 발생 이상치 → Artificial Outlier
- 자연 발생 이상치 → Natural Outlier
4️⃣ 이상값의 문제점
| 문제점 | 설명 | 영향 |
|---|---|---|
| 통계 분석 신뢰도 저하 |
이상값이 포함되면 평균, 분산 등의 통계값이 왜곡될 수 있음 |
평균 분산 회귀 분석 결과 왜곡 |
| 데이터 정규성 저하 |
이상값이 많으면 데이터 분포가 왜곡되어 정규분포 가정이 깨질 수 있음 |
통계 분석 가정 위반 모델 적용 어려움 |
| 분석 결과 왜곡 |
모델 학습 시 이상값이 포함되면 분석 결과가 왜곡될 수 있음 |
모델 학습 성능 저하 예측 정확도 감소 |
🎯 포인트
- 이상값 영향 → 평균 왜곡, 분산 증가, 통계 분석 신뢰도 감소
5️⃣ 이상값 탐지 방법
✅ 1. Box Plot (상자수염그림) ⭐
- 데이터 분포를 이용한 대표적인 시각화 방법

🔹 구성 요소
| 구성 요소 | 의미 | 설명 |
|---|---|---|
|
최소값 (Minimum) |
데이터 범위의 시작점 |
이상값을 제외한 데이터 중 가장 작은 값 하단 수염(Whisker)의 끝을 나타냄 |
|
Q1 (1사분위수) |
하위 25% 지점 |
데이터를 정렬했을 때 전체 데이터 중 하위 25%에 위치하는 값 박스(Box)의 시작 지점 |
|
중앙값 (Median) |
데이터의 중앙값 |
데이터를 정렬했을 때 가운데 위치하는 값 데이터 개수가 짝수인 경우 가운데 두 값의 평균으로 계산 |
|
Q3 (3사분위수) |
상위 75% 지점 |
데이터를 정렬했을 때 전체 데이터 중 상위 75%에 위치하는 값 박스(Box)의 끝 지점 |
|
최대값 (Maximum) |
데이터 범위의 끝점 |
이상값을 제외한 데이터 중 가장 큰 값 상단 수염(Whisker)의 끝을 나타냄 |
🔹 IQR 기반 이상값 판별
- IQR = Q3 - Q1
🔹 이상값 판단 기준
- Q1 - 1.5 × IQR 보다 작은 값
- Q3 + 1.5 × IQR 보다 큰 값
이 범위를 벗어나면 이상값으로 판단
🎯 포인트
- 정상범위 = Q1 - 1.5IQR ~ Q3 + 1.5IQR
✅ 2. 줄기-잎 그림 (Stem and Leaf Plot)
- 데이터를 자릿수 단위로 분리하여 표시

🔹 특징
- 데이터 분포 파악 가능
- 이상값 확인 가능
- 데이터의 원래 값 보존 가능
✅ 3. 산점도 (Scatter Plot)
- 두 변수 간 관계를 점 형태로 시각화
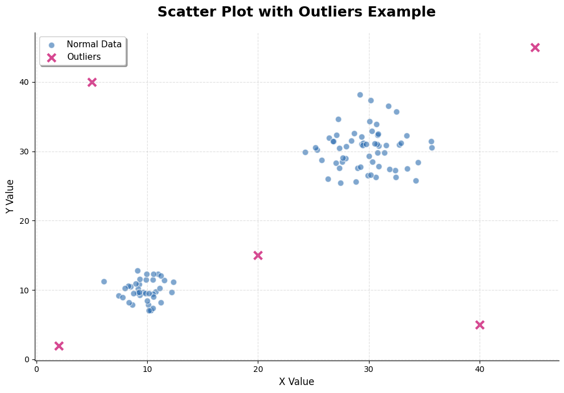
🔹 특징
- 멀리 떨어진 점 → 이상값으로 판단 가능
✅ 4. Z-score 기반 이상값 탐지 ⭐
- 데이터를 표준화하여 이상값 판단

🔹 Z-score 공식
μ = 평균
σ = 표준편차
- z = (x - μ) / σ
🔹 이상값 판단 기준
- ⚠️ 정규분포를 따른다는 가정이 필요
| 범위 | 데이터 비율 |
|---|---|
| 1σ | 68.27% |
| 2σ | 95.45% |
| 3σ | 99.73% |
🎯 포인트
- 일반적으로 |z| > 3 이면 이상값으로 판단
✅ 5. DBSCAN (밀도 기반 클러스터링)
- Density Based Spatial Clustering of Application with Noise
- 데이터 밀도 기반 군집화 알고리즘
- 군집에 속하지 않는 데이터는 Noise(이상값)로 판단

🔹 특징
- 데이터 밀도 기반 군집화
- 군집에 속하지 않는 데이터 → 이상값
✅ 6. Isolation Forest
- 이상값 탐지용 대표 머신러닝 알고리즘
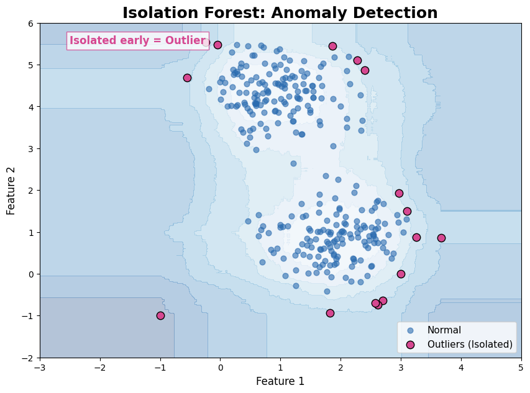
🔹 원리
- 데이터를 무작위로 분할
- 빨리 분리되는 데이터 → 이상값
🔹 특징
- 대용량 데이터 처리 가능
- 고차원 데이터에 적합
✅ 이상값 탐지 방법 비교표
| 방법 | 분류 | 핵심 원리 | 기준 / 특징 |
|---|---|---|---|
|
Box Plot (상자수염그림) |
시각화 | 사분위수(IQR)를 이용한 이상값 탐지 |
IQR = Q3 − Q1
[이상값 기준] Q1 − 1.5×IQR 이하 Q3 + 1.5×IQR 이상 |
|
Stem & Leaf Plot (줄기-잎 그림) |
시각화 | 데이터를 자릿수 단위로 분리하여 표현 |
데이터 분포 확인 가능 이상값 탐지 가능 |
|
Scatter Plot (산점도) |
시각화 | 두 변수 간 관계를 점으로 표현 |
다른 점들과 멀리 떨어진 점 → 이상값으로 판단 |
| Z-score | 통계 기반 | 데이터 표준화를 이용한 이상값 탐지 |
z = (x − μ) / σ
|z| > 3 → 이상값 (정규분포 가정 필요) |
| DBSCAN | 군집 기반 | 데이터 밀도를 기반으로 군집 형성 |
군집에 속하지 않는 데이터 → Noise(이상값) |
| Isolation Forest | 머신러닝 | 데이터를 무작위 분할하여 이상값 탐지 |
빠르게 분리되는 데이터 → 이상값으로 판단 대용량·고차원 데이터에 적합 |
🎯 포인트
- 대표 이상값 탐지 알고리즘 → DBSCAN, Isolation Forest
6️⃣ 이상값 처리 방법
| 처리 방법 | 설명 | 특징 | 예시 |
|---|---|---|---|
|
제거 (Removal) |
이상값을 데이터셋에서 삭제 |
장점: 분석 정확도 향상 단점: 데이터 손실 발생 |
이상값 행(row) 제거 |
|
대체 (Imputation) |
이상값을 다른 값으로 대체 | 데이터 손실 없이 처리 가능 |
평균값 대체 중앙값 대체 회귀 기반 대체 |
|
변환 (Transformation) |
데이터 변환을 통해 이상값 영향 완화 | 데이터 분포 왜곡 감소 |
로그 변환 정규화 표준화 |
📊 시험 포인트 정리
🔥 이상값 개념
- Outlier
- 정상 범위를 벗어난 값
🔥 이상값 종류
- Univariate Outlier
- Multivariate Outlier
🔥 이상값 탐지 방법 ⭐
- Box Plot
- Z-score
- DBSCAN
- Isolation Forest
🔥 Z-score 기준
- |z| > 3 → 이상값
🔥 IQR 기반 이상값 기준
- Q1 - 1.5IQR
- Q3 + 1.5IQR
📌 암기 핵심 요약
- 대표적인 이상값 탐지 방법
- Box Plot
- Z-score
- DBSCAN
- Isolation Forest

2026 이기적 빅데이터분석기사 필기 기본서
(저자: 나홍석, 배원성, 이건길, 이혜영 | 출판사: 영진닷컴)
※ 본 글은 위 교재를 참고하여 학습 목적으로 재정리한 내용입니다.
'Certifications > 빅데이터분석기사 필기' 카테고리의 다른 글
| [이기적] 가설검정 완전 정리 (귀무가설·대립가설 / 유의수준 / p-value / 1종·2종 오류) (0) | 2026.03.11 |
|---|---|
| [이기적] 데이터 탐색(EDA) 개요 정리 (EDA / 산포도 / 히스토그램 / 박스플롯) (0) | 2026.03.09 |
| [이기적] 결측값 처리 방법 정리 (MCAR / MAR / NMAR / 대치법) (0) | 2026.03.08 |
| [이기적] 데이터 전처리 개요 정리 (데이터 정제 / 결측값 처리 / 이상치 탐지) (1) | 2026.03.08 |
| [이기적] 데이터 분석 절차 정리 (데이터 분석 기획 / 분석 문제 정의 / Top-Down / Bottom-Up / 분석 준비도 / 분석 성숙도) (0) | 2026.03.07 |